Publications
...and preprints
2025
- COLING2025
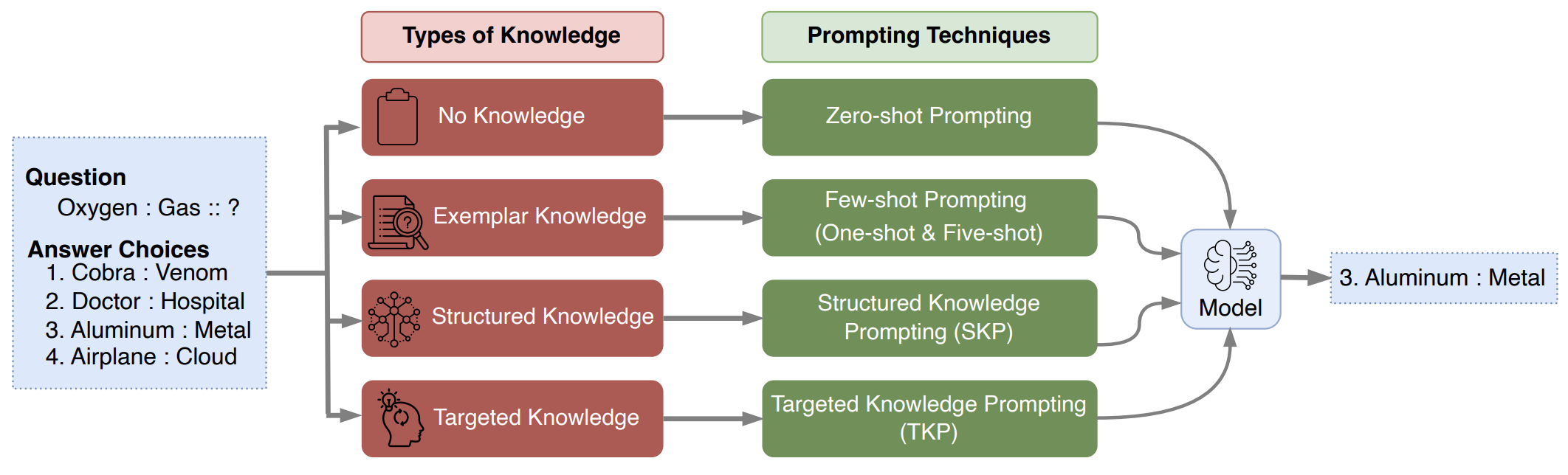 KnowledgePrompts: Exploring the Abilities of Large Language Models to Solve Proportional Analogies via Knowledge-Enhanced PromptingThilini Wijesiriwardene, Ruwan Wickramarachchi, Sreeram Vennam, and 5 more authorsIn The 31st International Conference on Computational Linguistics (COLING 2025), 2025
KnowledgePrompts: Exploring the Abilities of Large Language Models to Solve Proportional Analogies via Knowledge-Enhanced PromptingThilini Wijesiriwardene, Ruwan Wickramarachchi, Sreeram Vennam, and 5 more authorsIn The 31st International Conference on Computational Linguistics (COLING 2025), 2025Making analogies is fundamental to cognition. Proportional analogies, which consist of four terms, are often used to assess linguistic and cognitive abilities. For instance, completing analogies like “Oxygen is to Gas as \<blank\>is to \<blank\>” requires identifying the semantic relationship (e.g., “type of”) between the first pair of terms (“Oxygen” and “Gas”) and finding a second pair that shares the same relationship (e.g., “Aluminum” and “Metal”). In this work, we introduce a 15K Multiple-Choice Question Answering (MCQA) dataset for proportional analogy completion and evaluate the performance of contemporary Large Language Models (LLMs) in various knowledge-enhanced prompt settings. Specifically, we augment prompts with three types of knowledge: exemplar, structured, and targeted. Our results show that despite extensive training data, solving proportional analogies remains challenging for current LLMs, with the best model achieving an accuracy of 55%. Notably, we find that providing targeted knowledge can better assist models in completing proportional analogies compared to providing exemplars or collections of structured knowledge.
@inproceedings{wijesiriwardene2024exploring, title = {KnowledgePrompts: Exploring the Abilities of Large Language Models to Solve Proportional Analogies via Knowledge-Enhanced Prompting}, author = {Wijesiriwardene, Thilini and Wickramarachchi, Ruwan and Vennam, Sreeram and Jain, Vinija and Chadha, Aman and Das, Amitava and Kumaraguru, Ponnurangam and Sheth, Amit}, booktitle = {The 31st International Conference on Computational Linguistics (COLING 2025)}, year = {2025}, } - IEEE-IS2025
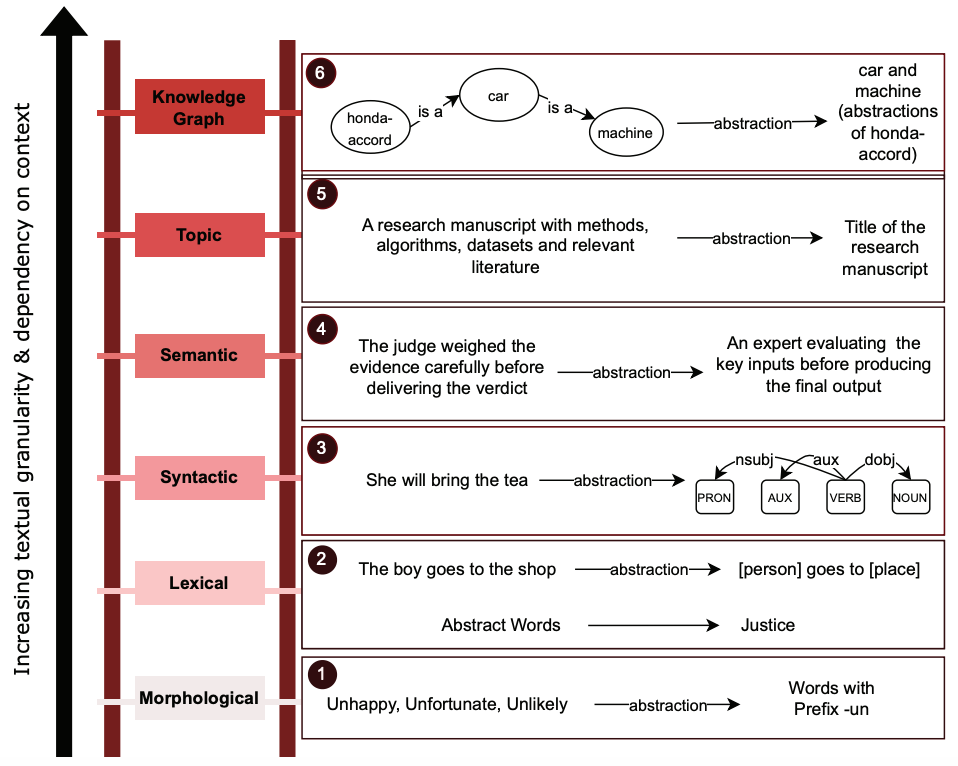 From Morphemes to Knowledge Graphs: Enabling Abstractions in Large Language Models with Neurosymbolic AIThilini Wijesiriwardene, Amit Sheth, and Krishnaprasad ThirunarayananIEEE Intelligent Systems, 2025
From Morphemes to Knowledge Graphs: Enabling Abstractions in Large Language Models with Neurosymbolic AIThilini Wijesiriwardene, Amit Sheth, and Krishnaprasad ThirunarayananIEEE Intelligent Systems, 2025Recent advances in large language models (LLMs) have revolutionized natural language processing, achieving impressive performance across a wide range of linguistic tasks. However, these successes often mask a critical limitation: Current evaluation paradigms provide little insight into how well LLMs handle linguistic abstractions, the very cognitive capability that underlies generalization, analogy-making, and systematic reasoning. Without a principled framework for evaluating abstraction, it remains unclear whether LLMs truly engage in abstractions and their nature, how consistently they do so, and to what extent these behaviors reflect genuine abstraction capabilities versus surface-level pattern matching. We propose a structured taxonomy of linguistic abstractions in natural language processing, spanning levels from morphology to knowledge graphs (KGs), organized along two key dimensions: linguistic granularity and contextual dependence. This taxonomy supports a more nuanced evaluation of LLMs’ abstraction capability and helps identify where current models fall short. In particular, we highlight the limitations of LLMs at higher levels of abstraction—such as semantic, topical, taxonomic, and KG levels—where relational composition, context sensitivity, and symbolic structures are critical. To remedy these weaknesses, we advocate for the integration of neurosymbolic artificial intelligence (AI) systems that combine neural representations with symbolic reasoning.
@article{11278230, title = {From Morphemes to Knowledge Graphs: Enabling Abstractions in Large Language Models with Neurosymbolic AI}, author = {Wijesiriwardene, Thilini and Sheth, Amit and Thirunarayanan, Krishnaprasad}, journal = {IEEE Intelligent Systems}, volume = {40}, number = {6}, pages = {80--86}, year = {2025}, publisher = {IEEE}, }
2024
- EACL2024
 On the Relationship between Sentence Analogy Identification and Sentence Structure Encoding in Large Language ModelsThilini Wijesiriwardene, Ruwan Wickramarachchi, Aishwarya Naresh Reganti, and 4 more authorsIn Findings of the Association for Computational Linguistics: EACL 2024, 2024
On the Relationship between Sentence Analogy Identification and Sentence Structure Encoding in Large Language ModelsThilini Wijesiriwardene, Ruwan Wickramarachchi, Aishwarya Naresh Reganti, and 4 more authorsIn Findings of the Association for Computational Linguistics: EACL 2024, 2024The ability of Large Language Models (LLMs) to encode syntactic and semantic structures of language is well examined in NLP. Additionally, analogy identification, in the form of word analogies are extensively studied in the last decade of language modeling literature. In this work we specifically look at how LLMs’ abilities to capture sentence analogies (sentences that convey analogous meaning to each other) vary with LLMs’ abilities to encode syntactic and semantic structures of sentences. Through our analysis, we find that LLMs’ ability to identify sentence analogies is positively correlated with their ability to encode syntactic and semantic structures of sentences. Specifically, we find that the LLMs which capture syntactic structures better, also have higher abilities in identifying sentence analogies.
@inproceedings{wijesiriwardene2024relationship, title = {On the Relationship between Sentence Analogy Identification and Sentence Structure Encoding in Large Language Models}, author = {Wijesiriwardene, Thilini and Wickramarachchi, Ruwan and Reganti, Aishwarya Naresh and Jain, Vinija and Chadha, Aman and Sheth, Amit and Das, Amitava}, booktitle = {Findings of the Association for Computational Linguistics: EACL 2024}, pages = {451--457}, year = {2024}, }
2023
- ACL2023
 ANALOGICAL-A Novel Benchmark for Long Text Analogy Evaluation in Large Language ModelsThilini Wijesiriwardene, Ruwan Wickramarachchi, Bimal Gajera, and 6 more authorsIn Findings of the Association for Computational Linguistics: ACL 2023, 2023
ANALOGICAL-A Novel Benchmark for Long Text Analogy Evaluation in Large Language ModelsThilini Wijesiriwardene, Ruwan Wickramarachchi, Bimal Gajera, and 6 more authorsIn Findings of the Association for Computational Linguistics: ACL 2023, 2023Over the past decade, analogies, in the form of word-level analogies, have played a significant role as an intrinsic measure of evaluating the quality of word embedding methods such as word2vec. Modern large language models (LLMs), however, are primarily evaluated on extrinsic measures based on benchmarks such as GLUE and SuperGLUE, and there are only a few investigations on whether LLMs can draw analogies between long texts. In this paper, we present ANALOGICAL, a new benchmark to intrinsically evaluate LLMs across a taxonomy of analogies of long text with six levels of complexity – (i) word, (ii) word vs. sentence, (iii) syntactic, (iv) negation, (v) entailment, and (vi) metaphor. Using thirteen datasets and three different distance measures, we evaluate the abilities of eight LLMs in identifying analogical pairs in the semantic vector space. Our evaluation finds that it is increasingly challenging for LLMs to identify analogies when going up the analogy taxonomy.
@inproceedings{wijesiriwardene2023analogical, title = {ANALOGICAL-A Novel Benchmark for Long Text Analogy Evaluation in Large Language Models}, author = {Wijesiriwardene, Thilini and Wickramarachchi, Ruwan and Gajera, Bimal and Gowaikar, Shreeyash and Gupta, Chandan and Chadha, Aman and Reganti, Aishwarya Naresh and Sheth, Amit and Das, Amitava}, booktitle = {Findings of the Association for Computational Linguistics: ACL 2023}, pages = {3534--3549}, year = {2023}, } - ESWC2023
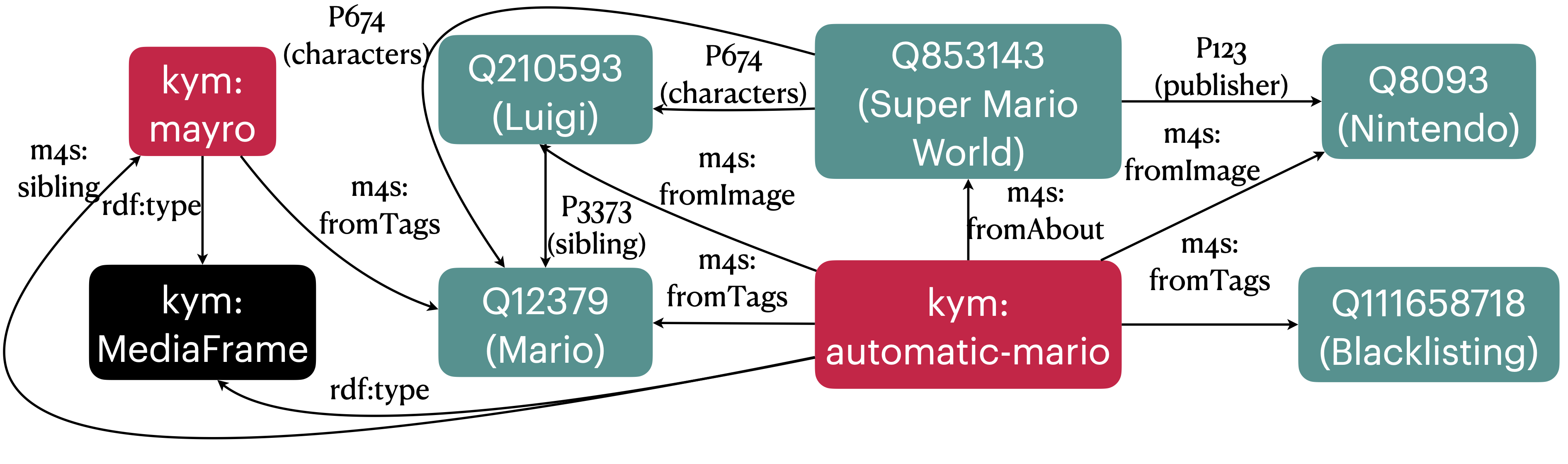 IMKG: The Internet Meme Knowledge GraphRiccardo Tommasini, Filip Ilievski, and Thilini WijesiriwardeneIn European Semantic Web Conference, 2023
IMKG: The Internet Meme Knowledge GraphRiccardo Tommasini, Filip Ilievski, and Thilini WijesiriwardeneIn European Semantic Web Conference, 2023Internet Memes (IMs) are creative media that combine text and vision modalities that people use to describe their situation by reusing an existing, familiar situation. Prior work on IMs has focused on analyzing their spread over time or high-level classification tasks like hate speech detection, while a principled analysis of their stratified semantics is missing. Hypothesizing that Semantic Web technologies are appropriate to help us bridge this gap, we build the first Internet Meme Knowledge Graph (IMKG): an explicit representation with 2 million edges that capture the semantics encoded in the text, vision, and metadata of thousands of media frames and their adaptations as memes. IMKG is designed to fulfil seven requirements derived from the inherent characteristics of IMs. IMKG is based on a comprehensive semantic model, it is populated with data from representative IM sources, and enriched with entities extracted from text and vision connected through background knowledge from Wikidata. IMKG integrates its knowledge both in RDF and as a labelled property graph. We provide insights into the structure of IMKG, analyze its central concepts, and measure the effect of knowledge enrichment from different information modalities. We demonstrate its ability to support novel use cases, like querying for IMs that are based on films, and we provide insights into the signal captured by the structure and the content of its nodes. As a novel publicly available resource, IMKG opens the possibility for further work to study the semantics of IMs, develop novel reasoning tasks, and improve its quality.
@inproceedings{tommasini2023correction, title = {IMKG: The Internet Meme Knowledge Graph}, author = {Tommasini, Riccardo and Ilievski, Filip and Wijesiriwardene, Thilini}, booktitle = {European Semantic Web Conference}, pages = {C1--C1}, year = {2023}, organization = {Springer}, } - IEEE-IS2023
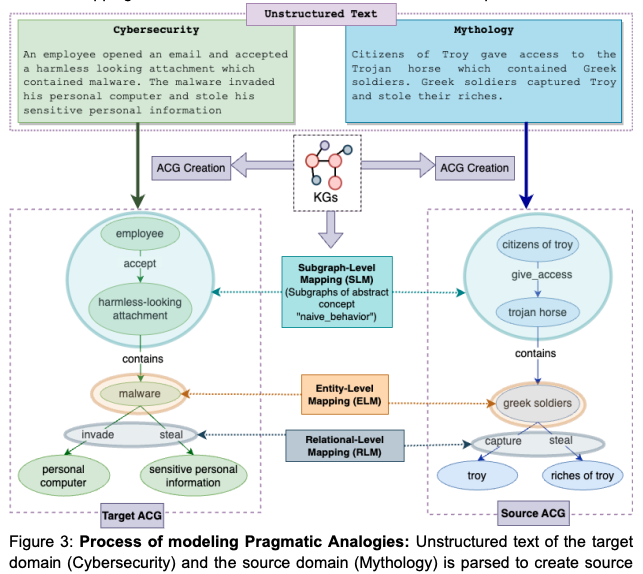 Why do we need neurosymbolic ai to model pragmatic analogies?Thilini Wijesiriwardene, Amit Sheth, Valerie L Shalin, and 1 more authorIEEE Intelligent Systems, 2023
Why do we need neurosymbolic ai to model pragmatic analogies?Thilini Wijesiriwardene, Amit Sheth, Valerie L Shalin, and 1 more authorIEEE Intelligent Systems, 2023Extended version: https://arxiv.org/pdf/2308.01936
A hallmark of intelligence is the ability to use a familiar domain to make inferences about a less familiar domain, known as analogical reasoning. In this article, we delve into the performance of Large Language Models (LLMs) in dealing with progressively complex analogies expressed in unstructured text. We discuss analogies at four distinct levels of complexity: lexical analogies, syntactic analogies, semantic analogies, and pragmatic analogies. As the analogies become complex, they require increasingly extensive, diverse knowledge beyond the textual content, unlikely to be found in the lexical cooccurrence statistics that power LLMs. To address this, we discuss the necessity of employing neurosymbolic AI techniques that combine statistical and symbolic AI, informing the representation of unstructured text to highlight and augment relevant content, provide abstraction and guide the mapping process. Our knowledge-informed approach maintains the efficiency of LLMs while preserving the ability to explain analogies for pedagogical applications.
@article{wijesiriwardene2023we, title = {Why do we need neurosymbolic ai to model pragmatic analogies?}, author = {Wijesiriwardene, Thilini and Sheth, Amit and Shalin, Valerie L and Das, Amitava}, journal = {IEEE Intelligent Systems}, volume = {38}, number = {5}, pages = {12--16}, year = {2023}, publisher = {IEEE}, }
{kind=link}
2022
- Web2022
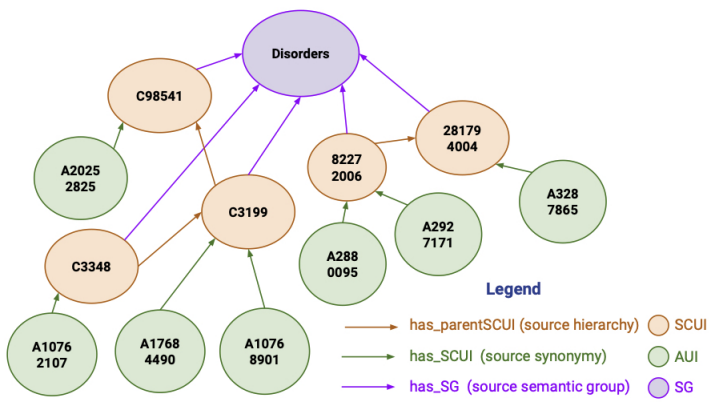 Context-enriched learning models for aligning biomedical vocabularies at scale in the UMLS MetathesaurusVinh Nguyen, Hong Yung Yip, Goonmeet Bajaj, and 5 more authorsIn Proceedings of the ACM Web Conference 2022, 2022
Context-enriched learning models for aligning biomedical vocabularies at scale in the UMLS MetathesaurusVinh Nguyen, Hong Yung Yip, Goonmeet Bajaj, and 5 more authorsIn Proceedings of the ACM Web Conference 2022, 2022The Unified Medical Language System (UMLS) Metathesaurus construction process mainly relies on lexical algorithms and manual expert curation for integrating over 200 biomedical vocabularies. A lexical-based learning model (LexLM) was developed to predict synonymy among Metathesaurus terms and largely outperforms a rule-based approach (RBA) that approximates the current construction process. However, the LexLM has the potential for being improved further because it only uses lexical information from the source vocabularies, while the RBA also takes advantage of contextual information. We investigate the role of multiple types of contextual information available to the UMLS editors, namely source synonymy (SS), source semantic group (SG), and source hierarchical relations (HR), for the UMLS vocabulary alignment (UVA) problem. In this paper, we develop multiple variants of context-enriched learning models (ConLMs) by adding to the LexLM the types of contextual information listed above. We represent these context types in context-enriched knowledge graphs (ConKGs) with four variants ConSS, ConSG, ConHR, and ConAll. We train these ConKG embeddings using seven KG embedding techniques. We create the ConLMs by concatenating the ConKG embedding vectors with the word embedding vectors from the LexLM. We evaluate the performance of the ConLMs using the UVA generalization test datasets with hundreds of millions of pairs. Our extensive experiments show a significant performance improvement from the ConLMs over the LexLM, namely +5.0% in precision (93.75%), +0.69% in recall (93.23%), +2.88% in F1 (93.49%) for the best ConLM. Our experiments also show that the ConAll variant including the three context types takes more time, but does not always perform better than other variants with a single context type. Finally, our experiments show that the pairs of terms with high lexical similarity benefit most from adding contextual information, namely +6.56% in precision (94.97%), +2.13% in recall (93.23%), +4.35% in F1 (94.09%) for the best ConLM. The pairs with lower degrees of lexical similarity also show performance improvement with +0.85% in F1 (96%) for low similarity and +1.31% in F1 (96.34%) for no similarity. These results demonstrate the importance of using contextual information in the UVA problem.
@inproceedings{nguyen2022context, title = {Context-enriched learning models for aligning biomedical vocabularies at scale in the UMLS Metathesaurus}, author = {Nguyen, Vinh and Yip, Hong Yung and Bajaj, Goonmeet and Wijesiriwardene, Thilini and Javangula, Vishesh and Parthasarathy, Srinivasan and Sheth, Amit and Bodenreider, Olivier}, booktitle = {Proceedings of the ACM Web Conference 2022}, pages = {1037--1046}, year = {2022}, } - arXiv
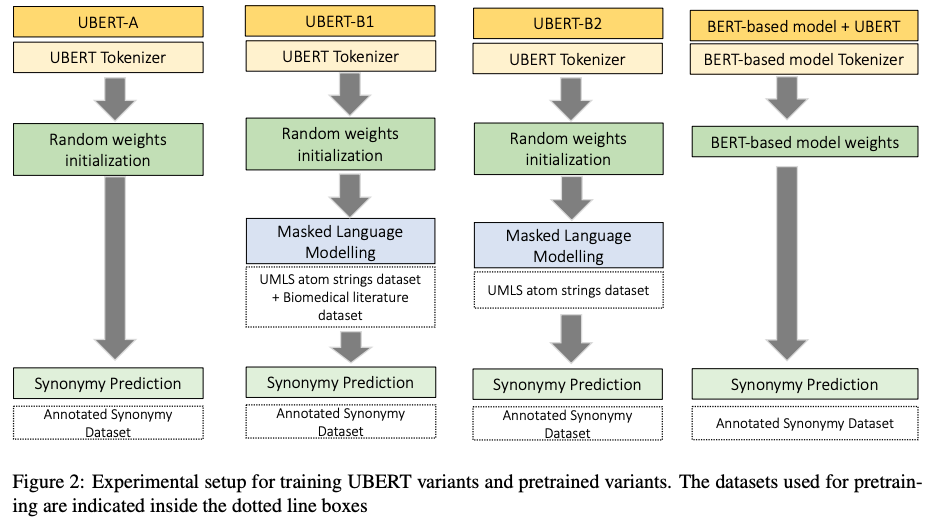 Ubert: A novel language model for synonymy prediction at scale in the umls metathesaurusThilini Wijesiriwardene, Vinh Nguyen, Goonmeet Bajaj, and 7 more authorsarXiv preprint arXiv:2204.12716, 2022
Ubert: A novel language model for synonymy prediction at scale in the umls metathesaurusThilini Wijesiriwardene, Vinh Nguyen, Goonmeet Bajaj, and 7 more authorsarXiv preprint arXiv:2204.12716, 2022The UMLS Metathesaurus integrates more than 200 biomedical source vocabularies. During the Metathesaurus construction process, synonymous terms are clustered into concepts by human editors, assisted by lexical similarity algorithms. This process is error-prone and time-consuming. Recently, a deep learning model (LexLM) has been developed for the UMLS Vocabulary Alignment (UVA) task. This work introduces UBERT, a BERT-based language model, pretrained on UMLS terms via a supervised Synonymy Prediction (SP) task replacing the original Next Sentence Prediction (NSP) task. The effectiveness of UBERT for UMLS Metathesaurus construction process is evaluated using the UMLS Vocabulary Alignment (UVA) task. We show that UBERT outperforms the LexLM, as well as biomedical BERT-based models. Key to the performance of UBERT are the synonymy prediction task specifically developed for UBERT, the tight alignment of training data to the UVA task, and the similarity of the models used for pretrained UBERT.
@article{wijesiriwardene2022ubert, title = {Ubert: A novel language model for synonymy prediction at scale in the umls metathesaurus}, author = {Wijesiriwardene, Thilini and Nguyen, Vinh and Bajaj, Goonmeet and Yip, Hong Yung and Javangula, Vishesh and Mao, Yuqing and Fung, Kin Wah and Parthasarathy, Srinivasan and Sheth, Amit P and Bodenreider, Olivier}, journal = {arXiv preprint arXiv:2204.12716}, year = {2022}, } - Workshop2022
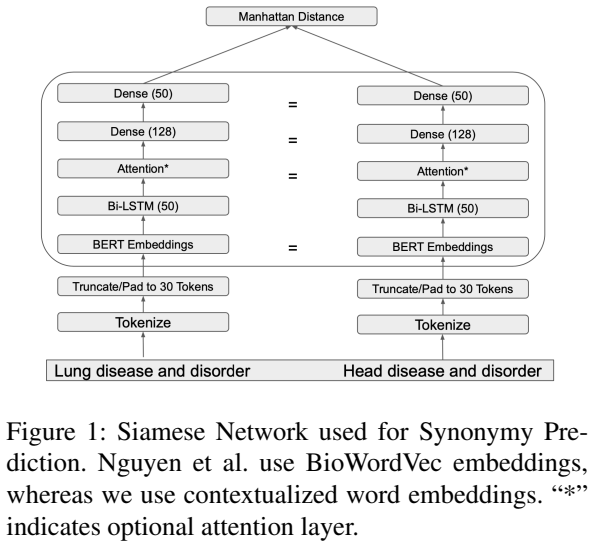 Evaluating Biomedical Word Embeddings for Vocabulary Alignment at Scale in the UMLS Metathesaurus Using Siamese NetworksGoonmeet Bajaj, Vinh Nguyen, Thilini Wijesiriwardene, and 5 more authorsIn Proceedings of the Third Workshop on Insights from Negative Results in NLP, May 2022
Evaluating Biomedical Word Embeddings for Vocabulary Alignment at Scale in the UMLS Metathesaurus Using Siamese NetworksGoonmeet Bajaj, Vinh Nguyen, Thilini Wijesiriwardene, and 5 more authorsIn Proceedings of the Third Workshop on Insights from Negative Results in NLP, May 2022Recent work uses a Siamese Network, initialized with BioWordVec embeddings (distributed word embeddings), for predicting synonymy among biomedical terms to automate a part of the UMLS (Unified Medical Language System) Metathesaurus construction process. We evaluate the use of contextualized word embeddings extracted from nine different biomedical BERT-based models for synonym prediction in the UMLS by replacing BioWordVec embeddings with embeddings extracted from each biomedical BERT model using different feature extraction methods. Finally, we conduct a thorough grid search, which prior work lacks, to find the best set of hyperparameters. Surprisingly, we find that Siamese Networks initialized with BioWordVec embeddings still out perform the Siamese Networks initialized with embedding extracted from biomedical BERT model.
@inproceedings{bajaj-etal-2022-evaluating, title = {Evaluating Biomedical Word Embeddings for Vocabulary Alignment at Scale in the {UMLS} {M}etathesaurus Using {S}iamese Networks}, author = {Bajaj, Goonmeet and Nguyen, Vinh and Wijesiriwardene, Thilini and Yip, Hong Yung and Javangula, Vishesh and Sheth, Amit and Parthasarathy, Srinivasan and Bodenreider, Olivier}, editor = {Tafreshi, Shabnam and Sedoc, Jo{\~a}o and Rogers, Anna and Drozd, Aleksandr and Rumshisky, Anna and Akula, Arjun}, booktitle = {Proceedings of the Third Workshop on Insights from Negative Results in NLP}, month = may, year = {2022}, address = {Dublin, Ireland}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2022.insights-1.11}, doi = {10.18653/v1/2022.insights-1.11}, pages = {82--87}, } - Analogies22@ICCBR
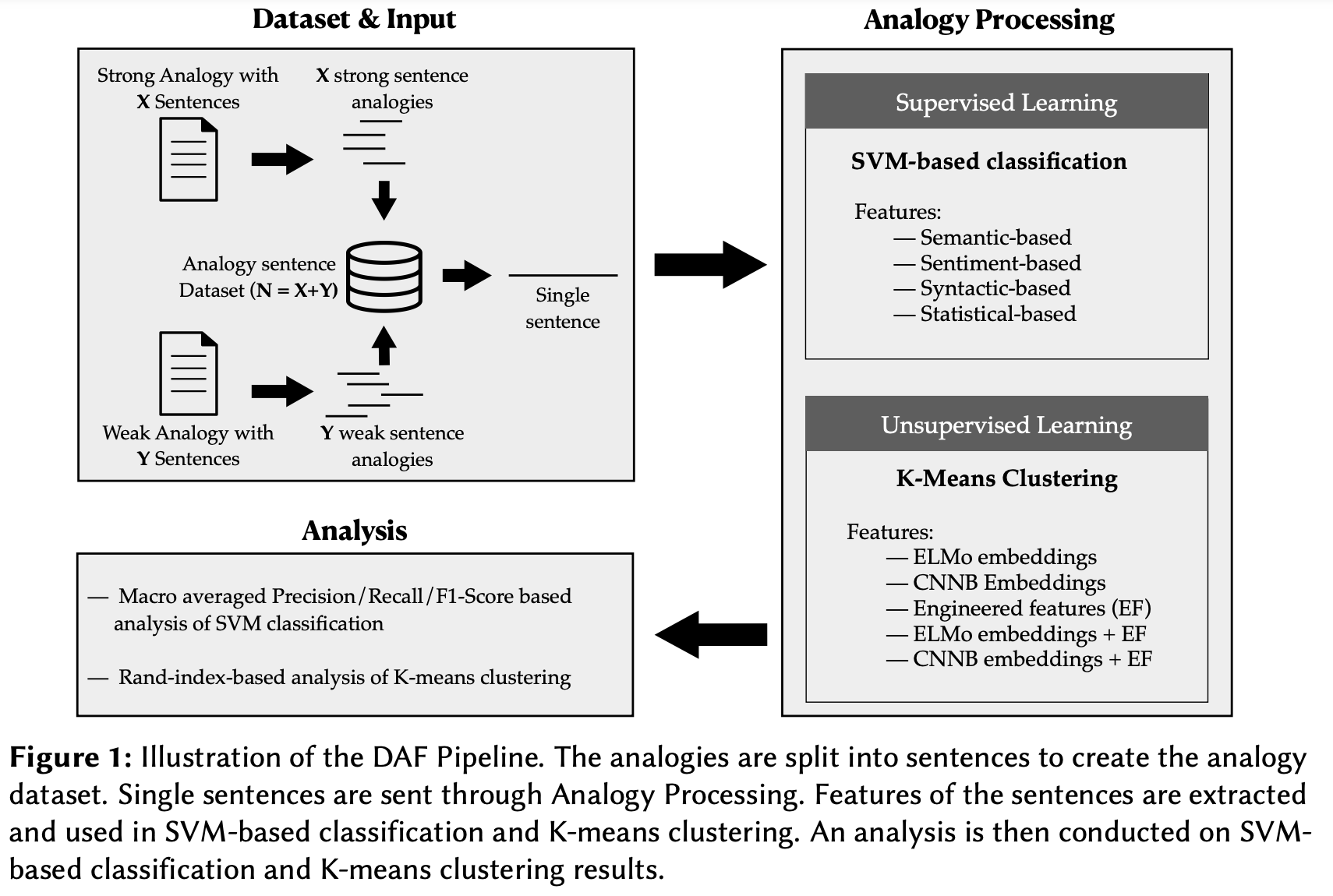 Towards efficient scoring of student-generated long-form analogies in STEMThilini Wijesiriwardene, Ruwan Wickramarachchi, Valerie L Shalin, and 1 more authorIn The International Conference on Case-Based Reasoning (ICCBR) Analogies’22: Workshop on Analogies: from Theory to Applications at ICCBR-2022, September, 2022, Nancy, France, May 2022
Towards efficient scoring of student-generated long-form analogies in STEMThilini Wijesiriwardene, Ruwan Wickramarachchi, Valerie L Shalin, and 1 more authorIn The International Conference on Case-Based Reasoning (ICCBR) Analogies’22: Workshop on Analogies: from Theory to Applications at ICCBR-2022, September, 2022, Nancy, France, May 2022Switching from an analogy pedagogy based on comprehension to analogy pedagogy based on production raises an impractical manual analogy scoring problem. Conventional symbol-matching approaches to computational analogy evaluation focus on positive cases, and challenge computational feasibility. This work presents the Discriminative Analogy Features (DAF) pipeline to identify the discriminative features of strong and weak long-form text analogies. We introduce four feature categories (semantic, syntactic, sentiment, and statistical) used with supervised vector-based learning methods to discriminate between strong and weak analogies. Using a modestly sized vector of engineered features with SVM attains a 0.67 macro F1 score. While a semantic feature is the most discriminative, out of the top 15 discriminative features, most are syntactic. Combining this engineered features with an ELMo-generated embedding still improves classification relative to an embedding alone. While an unsupervised K-Means clustering-based approach falls short, similar hints of improvement appear when inputs include the engineered features used in supervised learning.
The work presents the Discriminative Analogy Features (DAF) pipeline to identify the discriminative features (semantic, syntactic, sentiment, and statistical) of strong and weak long-form text analogies. While a semantic feature is the most discriminative, out of the top 15 discriminative features, most are syntactic.
@inproceedings{wijesiriwardene2022towards, title = {Towards efficient scoring of student-generated long-form analogies in STEM}, author = {Wijesiriwardene, Thilini and Wickramarachchi, Ruwan and Shalin, Valerie L and Sheth, Amit P}, booktitle = {The International Conference on Case-Based Reasoning (ICCBR) Analogies’22: Workshop on Analogies: from Theory to Applications at ICCBR-2022, September, 2022, Nancy, France}, year = {2022} }
2020
- SocInfo2020
 Alone: A dataset for toxic behavior among adolescents on twitterThilini Wijesiriwardene, Hale Inan, Ugur Kursuncu, and 5 more authorsIn Social Informatics: 12th International Conference, SocInfo 2020, Pisa, Italy, October 6–9, 2020, Proceedings 12, May 2020
Alone: A dataset for toxic behavior among adolescents on twitterThilini Wijesiriwardene, Hale Inan, Ugur Kursuncu, and 5 more authorsIn Social Informatics: 12th International Conference, SocInfo 2020, Pisa, Italy, October 6–9, 2020, Proceedings 12, May 2020Please contact thilini[at]sc.edu to request the dataset
The convenience of social media has also enabled its misuse, potentially resulting in toxic behavior. Nearly 66% of internet users have observed online harassment, and 41% claim personal experience, with 18% facing severe forms of online harassment. This toxic communication has a significant impact on the well-being of young individuals, affecting mental health and, in some cases, resulting in suicide. These communications exhibit complex linguistic and contextual characteristics, making recognition of such narratives challenging. In this paper, we provide a multimodal dataset of toxic social media interactions between confirmed high school students, called ALONE (AdoLescents ON twittEr), along with descriptive explanation. Each instance of interaction includes tweets, images, emoji and related metadata. Our observations show that individual tweets do not provide sufficient evidence for toxic behavior, and meaningful use of context in interactions can enable highlighting or exonerating tweets with purported toxicity.
Individual tweets do not provide sufficient evidence for toxic behavior, and meaningful use of context in interactions can enable highlighting or exonerating tweets with purported toxicity. A dataset is introcuded which consists of individual tweets along with their context.
@inproceedings{wijesiriwardene2020alone, title = {Alone: A dataset for toxic behavior among adolescents on twitter}, author = {Wijesiriwardene, Thilini and Inan, Hale and Kursuncu, Ugur and Gaur, Manas and Shalin, Valerie L and Thirunarayan, Krishnaprasad and Sheth, Amit and Arpinar, I Budak}, booktitle = {Social Informatics: 12th International Conference, SocInfo 2020, Pisa, Italy, October 6--9, 2020, Proceedings 12}, pages = {427--439}, year = {2020}, organization = {Springer}, }
2013
- IBIMA2013Optimization of partial palmprint identification process using palmprint segmentationThilini I Wijesiriwardene, Janitha R Karunawallabha, Vajisha U Wanniarachchi, and 2 more authorsIn International Business Information Management 2013, May 2013
Partial-to-full palmprint matching has attracted the experts in print identification area and researchers in palmprint matching. An efficient partial palmprint identification approach can increase the efficiency of the criminal investigation process in Sri Lanka as well as in other countries. This research investigates the existing researches done so far in order to achieve the challenges and limitations in palmprint matching. In this paper, the design of a segment based partial-to-full palmprint identification approach is presented which consists of three main modules: segment identification, hand type identification and minutiae matching.
Introduces a design of a segment based partial-to-full palmprint identification approach consisting of three main modules: segment identification, hand type identification and minutiae matching.
@inproceedings{wijesiriwardene2013optimization, title = {Optimization of partial palmprint identification process using palmprint segmentation}, author = {Wijesiriwardene, Thilini I and Karunawallabha, Janitha R and Wanniarachchi, Vajisha U and Dharmaratne, Anuja T and Sandaruwan, Damitha}, booktitle = {International Business Information Management 2013}, pages = {641--648}, year = {2013}, organization = {IBIMA Publishing}, url = {https://ibima.org/accepted-paper/a-novel-approach-to-optimize-crime-investigation-process-using-palmprint-recognition/} } - ICTER2013A Novel Approach to Optimize Crime Investigation Process Using Palmprint RecognitionJanitha R Karunawallabha, Thilini I Wijesiriwardene, U Wanniarachchi Vajisha, and 2 more authorsIn 2013 International Conference on Advances in ICT for Emerging Regions, IEEE, May 2013
A crime investigation is generally carried out to aid the crime solving process by identifying criminals and in some cases victims. Print evidence plays a crucial part in identifying criminals or suspects. According to Sri Lankan Criminal Records, 30%-35% of the print evidences are in the form of partial palmprints. Partial-to-full palmprint matching has attracted the experts in print identification area and researchers in palmprint matching. An efficient partial palmprint identification approach can increase the efficiency of the criminal investigation process in Sri Lanka as well as in other countries.
@inproceedings{karunawallabha2013novel, title = {A Novel Approach to Optimize Crime Investigation Process Using Palmprint Recognition}, author = {Karunawallabha, Janitha R and Wijesiriwardene, Thilini I and Vajisha, U Wanniarachchi and Anuja, T. Dharmaratne and Damitha, Sandaruwan}, booktitle = {2013 International Conference on Advances in ICT for Emerging Regions, IEEE}, year = {2013} }